Comenzar a usar la Brain Imaging Data Structure (BIDS)
Que es BIDS?
BIDS: Brain Imaging Data Structure es una forma de estructurar todos los datos obtenidos en experimentos de Neuroimágenes (MRI, fMRI, EEG, iEEG, conducta, etc)
Un ejemplo de como quedaría organizado el arbol de directorios se puede ver en esta imagen:
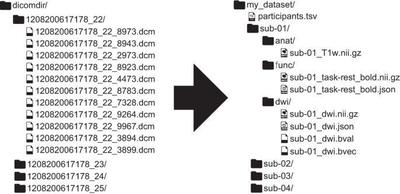
La recomendación es ingresar primero al sitio principal del estándar y mirar también los detalles del estándar (v1.4.0) para entender el árbol de directorios y archivos requeridos.
Video-tutoriales como para arrancar:
- The benefits of BIDS - BrainHack 2020 de OHBM
- Brain Imaging Data Standards BIDS for EEG - Dr. Cyril Pernet, Sapiens Lab
A continuación voy a listar algunos de los recursos mas útiles que vaya encontrando y una breve descripción:
-
BIDS Starter Kit: Como primer paso recomiendo ingresar al BIDS Starter Kit. Es un repositorio alojado en github con lo necesario para arrancar.
- BIDS wiki: La wiki tiene varios recursos básicos para introducirse a la filosofía en la que se basa el estándar, los tipos de archivos principales que se usan para enriquecer la info que se registra de nuestros datos. También hay tutoriales, datasets de ejemplo, presentaciones/recursos/links para profundizar.
- Validador del formato: Una herramienta muy importante es el validador que nos permite verificar si un dataset cumple con los requerimientos de BIDS.
- Comunidad Neurostars: Para tener la posibilidad de hacer preguntas y contactar a la comunidad recomiendan el uso de la plataforma Neurostars. Alli también se pueden hacer consultas sobre otras ramas de neuroimágenes.
- BIDS Apps: Otra cosa muy útil son una serie de apps (BIDS Apps), que reciben como entrada un dataset organizado siguiendo BIDS y permiten aplicar un pipeline de procesamiento determinado. Las apps viene enpaquetadas en imágenes de Docker/Singularity. Hay varios desarrollos ya disponibles para usar, aunque la mayoría son para MRI/fMRI.
-
PyBIDS es una librería con funciones para interactuar con BIDS, usando python. Permite crear un layout del dataset para poder recorrerlo y acceder a los archivos. Tiene funcionalidades para crear un reporte y finalmente herramientas para crear modelos lineales (GLMs) a partir del dataset.
-
Repositorio de Robert Oostenveld: Un repositorio que me ayudó mucho a organizar mis datos es el de Robert Oostenveld. Tiene una serie de scripts para organizar/reorganizar archivos. Me resultó muy útil uno que permite crear todos los archivos accesorios del dataset (create sidecar files), en caso de que haya faltantes (incorpora los obligatorios y algunos opcionales). También permite chequear si está todo bien de acuerdo al estándar.
Agustin Solano
PhD Student
My research interests include cognitive neuroscience, motor memories and signal processing. matter.